The generation of synthetic images has greatly advanced in recent years due to the progress of artificial intelligence. Some of the applications have recently been widely popularized in media, especially art and fashion generation and videos/photos creation of realistic-looking human faces¹. The image-to-image translation is a special case of synthetic image generation, where input images from one domain are translated into synthetic images in another domain.
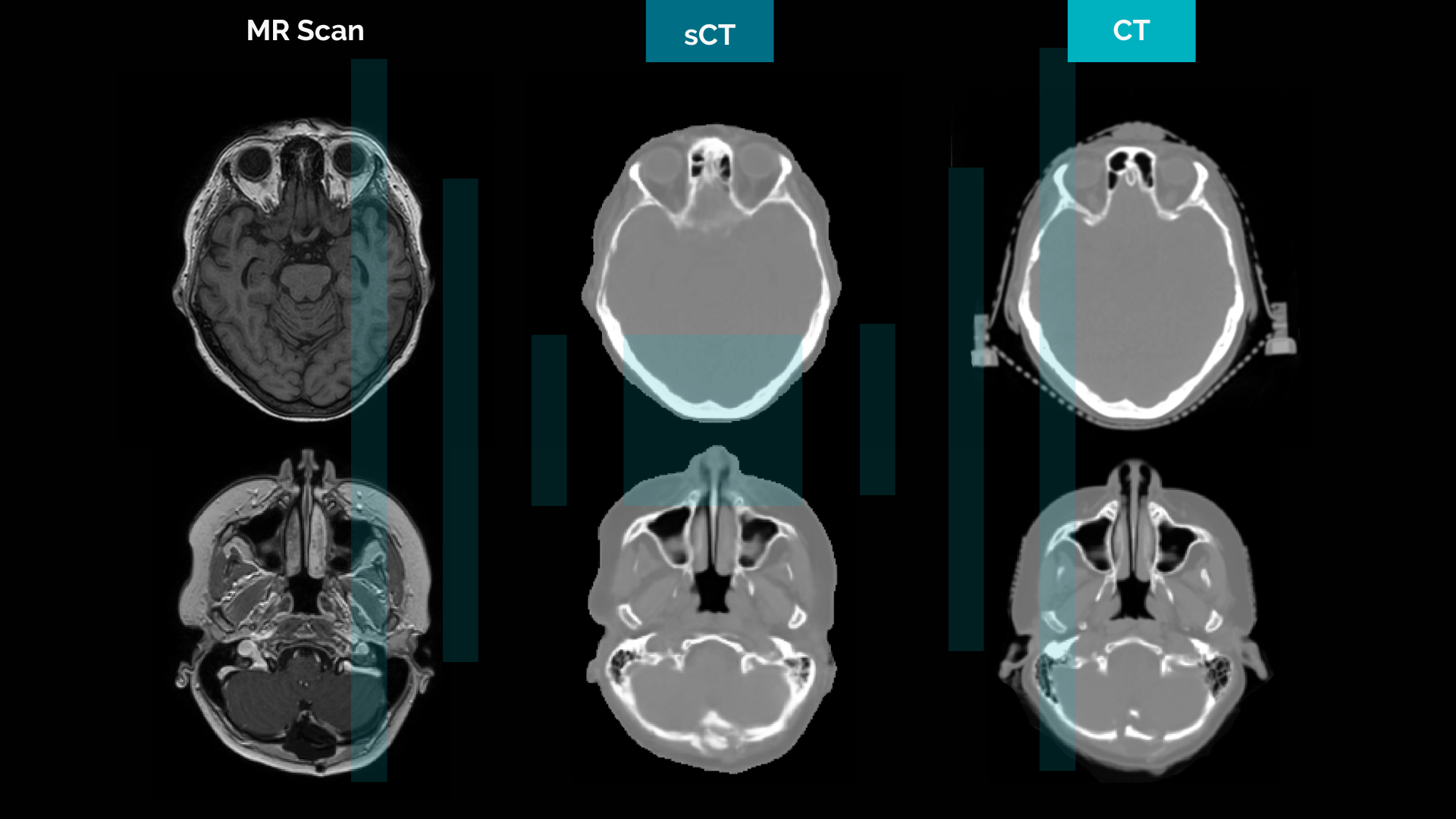
A non-exhaustive list of example cases includes edges-to-photo translation, and labels-to-street scene translation, as shown in Figure 1. Various potential industrial applications exist for image-to-image translation such as fashion design, game development, self-driving cars engineering, or medical applications deployment where translation can be used for image augmentation/enhancement or converting modalities between them (MR to CT for example for radiation therapy planning).

Generative adversarial networks (GANs) are a class of generative models that can be used for various synthetic data generation tasks. GANs have gained a lot of interest in recent years due to their impressive results in image generation², including image-to-image translation³′⁴. A GAN model consists of at least one generator network and a discriminator network. Figure 2 illustrates the training of a GAN model for MR-to-CT translation with training data consisting of pairs of real MR and CT images. The generator takes real MR images as input and generates synthetic CT images. The discriminator learns to classify real and synthetic CT images as real or fake. This drives the generator to learn to generate more realistic synthetic images that are indistinguishable from real images. The training of a GAN can be seen as a competition between the two networks, the generator and the discriminator, where the generator attempts to fool the discriminator.

Developing image-to-image translation models typically requires a training dataset containing multiple pairs of images aligned voxel-wise, such as MR and CT images for each patient. Since obtaining paired data can be a time-consuming and costly task (or even impossible in some scenarios), interest has grown in developing models which can be trained with unpaired data, for example, a set of MR images from some patients and a set of CT images coming from other patients. Despite widely available data, the training becomes a more challenging task as the performance of the models demonstrates, which tends to fall behind the paired image method. Hence, developing and improving unpaired methods remains an active area of research.
Image-to-image translation has the potential to improve many applications in the medical field. Given sufficient amount and quality of data, tasks in image space e.g. image denoising, resolution increase, or artifact removal become feasible. Modality conversion, such as MR-to-CT, and PET-to-CT can help to reduce the imaging burden to capture multiple sequences at clinics, especially when diagnostic performance is not the main priority. Synthetically generated images can also be used to enlarge or augment training datasets required by machine learning models minimizing data collection in the clinic. Reducing costs may also be a benefit when a manual annotation is required (organ segmentation task as an example).
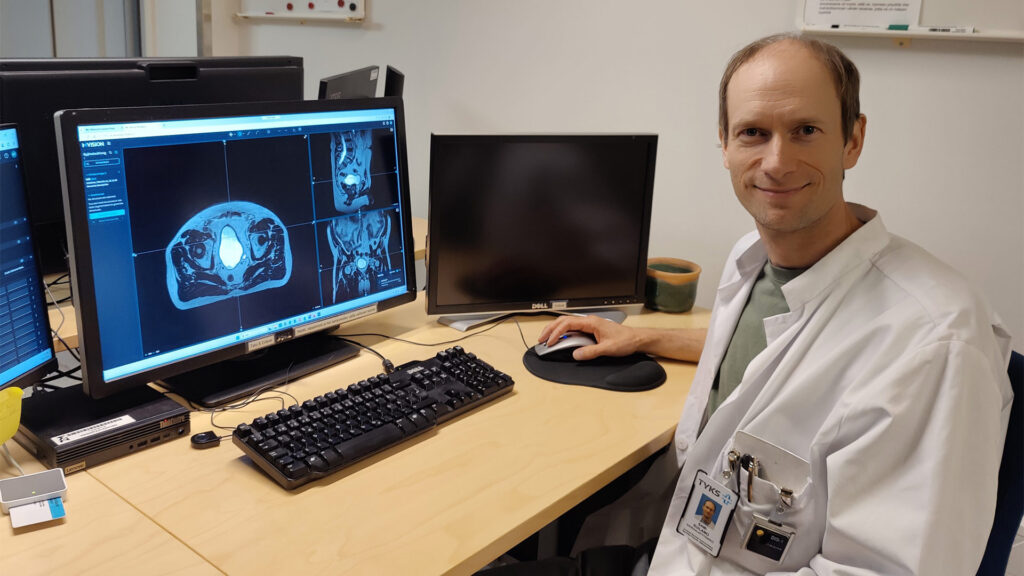
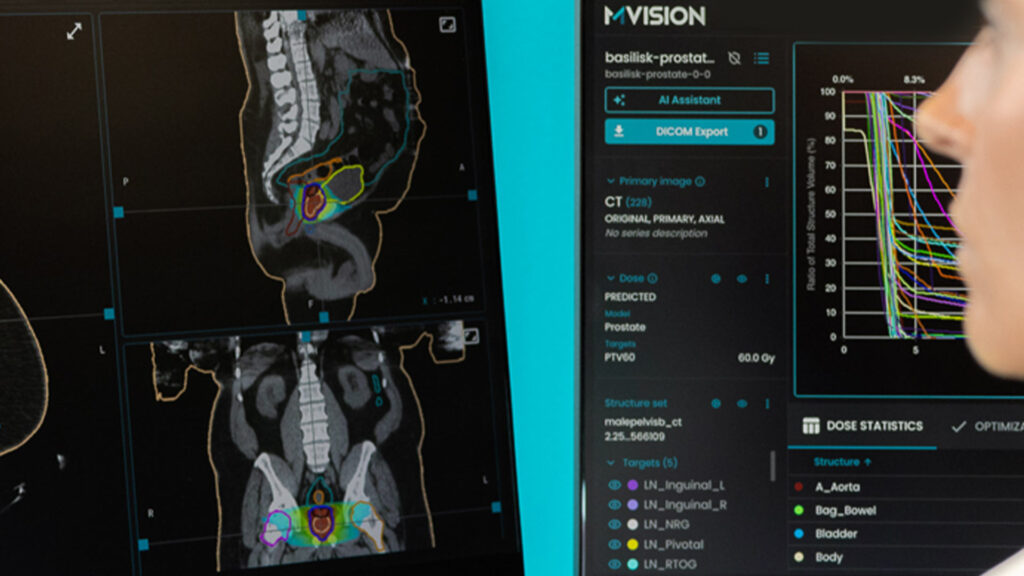
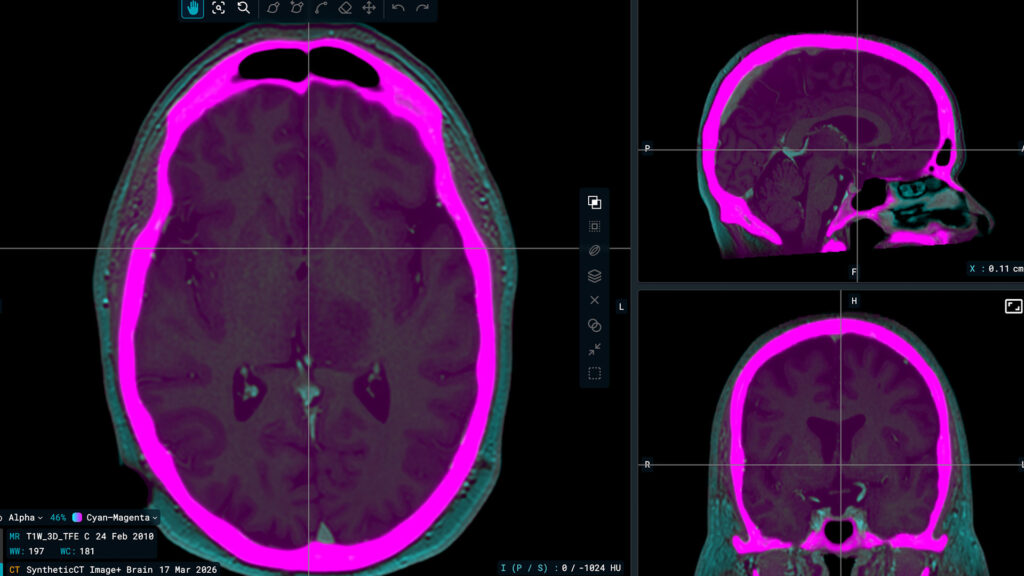
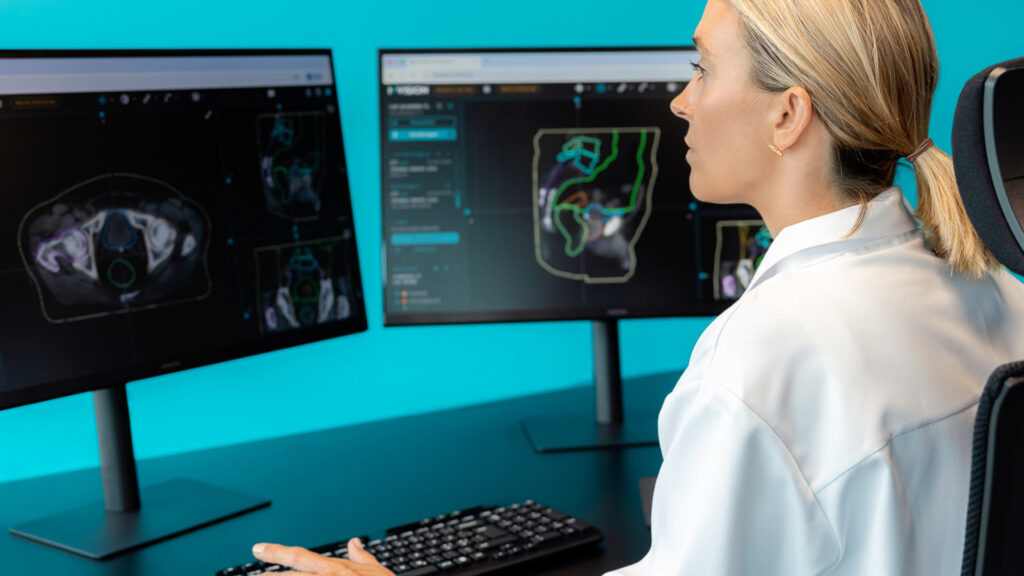
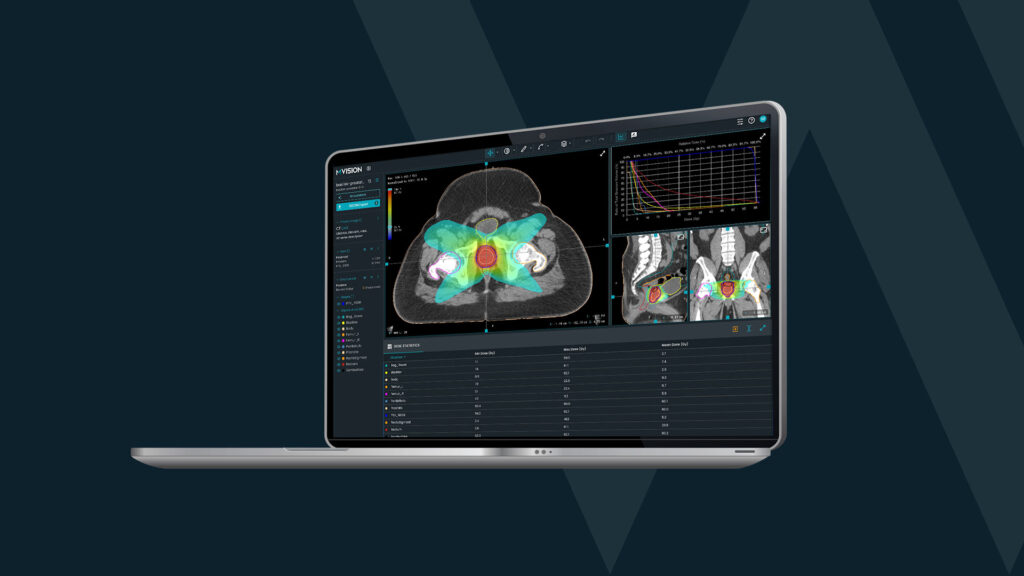
Due to its inherent superior soft tissue contrast over CT and the development of high-fidelity machines, MR has become a popular imaging modality in radiotherapy. However, because dose calculation algorithms require a correlation between image intensities and high-energy photon beam attenuation, CT images are still used as the main modality for radiation therapy planning. The capability to generate synthetic CT from specific MR sequences makes MR-only workflows possible in external beam radiotherapy, eliminating the need for dedicated CT imaging. Many developments have been published in the literature and some AI and non-AI commercial products are now used in clinics. With an exhaustive high-quality training dataset, deep learning (DL) -based models tend to produce more realistic-looking synthetic CT images in comparison to standard classification methods. However, since GANs and other DL-based methods may sometimes fail (producing errors or artifacts), the need for automatic methods to validate and verify the fidelity of the generated synthetic images becomes important.
We expect image generation and image-to-image translation to continue to be an increasingly active research and development area in the near future, with the emergence of many applications and products in the industry, as the models, evaluation methods, and training data collections improve. Data privacy regulations may become stricter in many countries, and in this context synthetic image generation has the potential to reduce the need for patient-specific data with methods to generate fully-synthetic datasets which can be used for machine learning model development.
- K. Hill and J. White. Designed to deceive: Do these people look real to you? The New York Times, 11 2020.
- Karras, T., Aittala, M., Laine, S., Härkönen, E., Hellsten, J., Lehtinen, J., & Aila, T. (2021). Alias-free generative adversarial networks. Advances in Neural Information Processing Systems, 34, 852-863.
- Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1125-1134).
- Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision (pp. 2223-2232).