



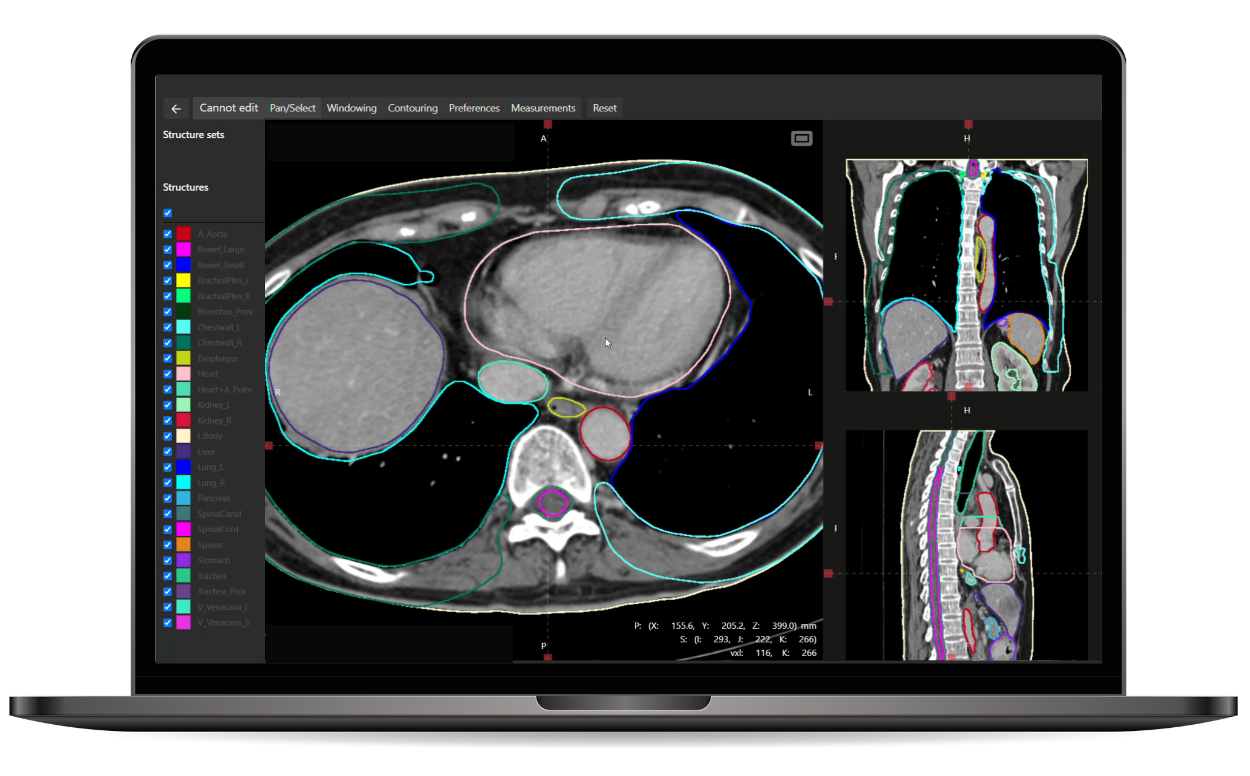
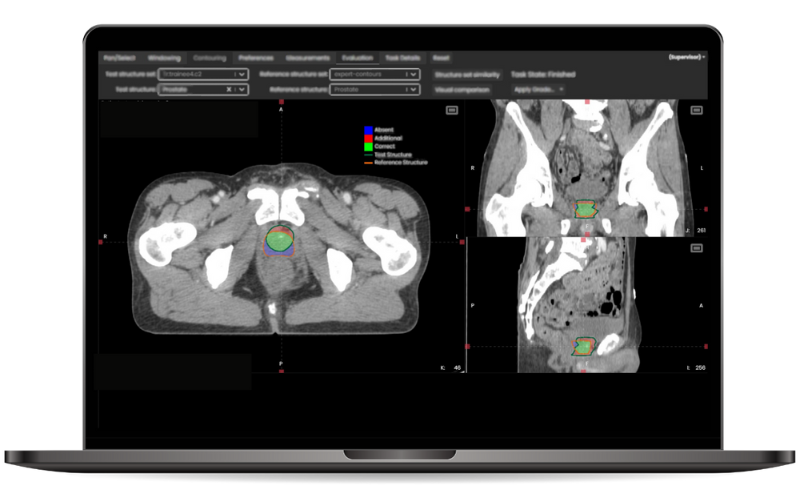
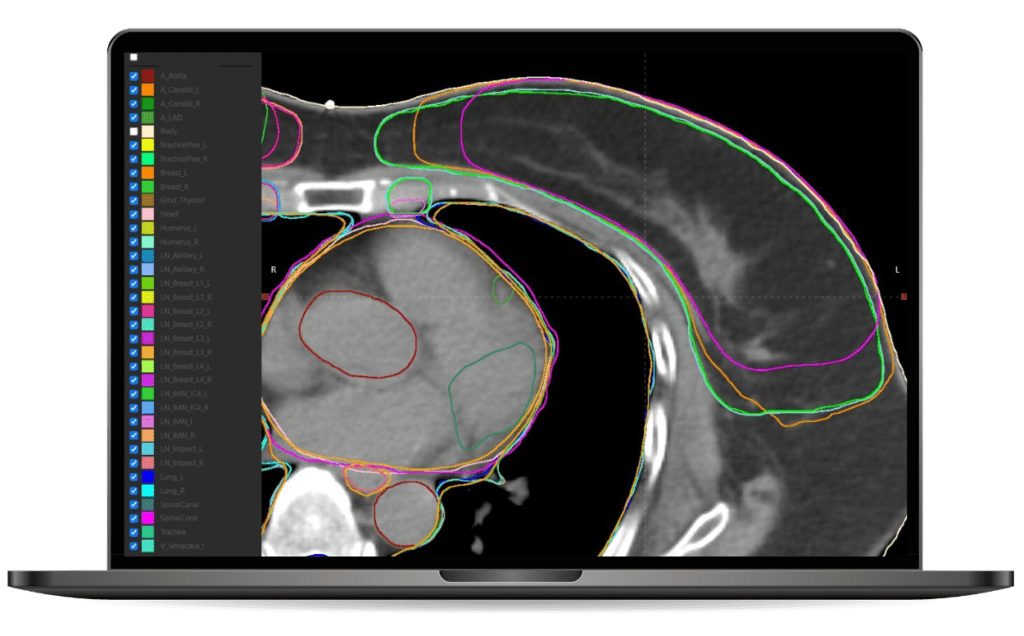
“The accuracy of organ-at-risk (OAR) contouring can significantly influence cancer treatment planning. Contour+, powered by AI, not only assists us in contouring these critical organs to protect them but also enables us to achieve much greater precision while saving time“
Dr. Jean Christophe FaivreHead of Radiation Therapy Department, Institut de Cancérologie de Lorraine (Nancy), France 
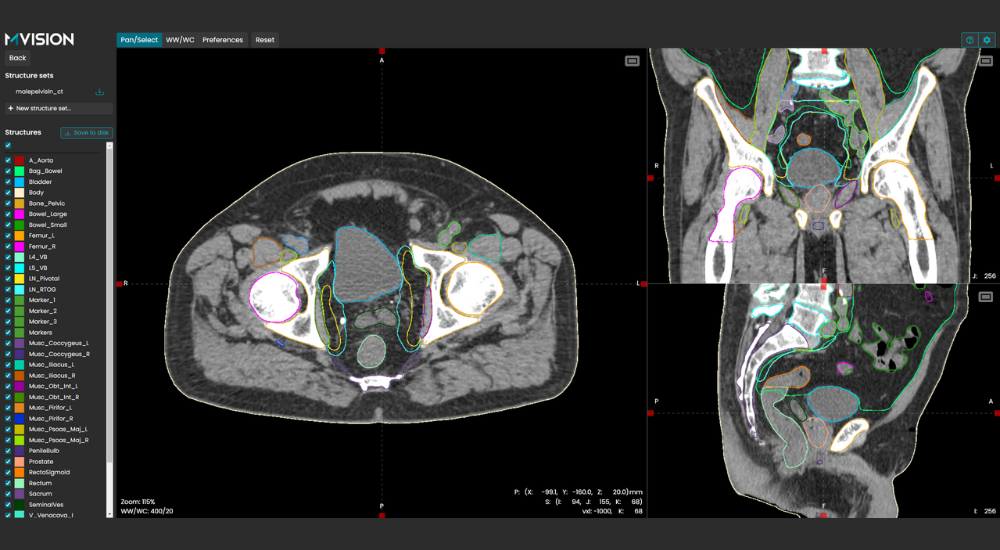
“We have a great improvement of our clinical workflow. We have gained one day just using MVision AI, we don’t need anymore staff, it was four hours of work to contour, now it is ten minutes.”
Marc PachoudHead of Radiotherapy Department, Riviera Chablais Hospital, Switzerland
“MVision AI is assisting our dosimetrists with the field placement, it has reduced some of the variations in our workflow. We only have one match plane position which has greatly simplified things. We have predominantly eliminated this field valuation task for the clinicians and not only does that save clinicians time but that was something that often was a delaying item in the process, so there is a sense that this could speed things up.”
Samantha WarrenMedical Physics, Northern Cancer Centre, UK 
"We have imaged and treated our prostate cancer patients during the same day with the help of MVisionAI’s auto-segmentation. Now we can schedule for shorter waiting times with more confidence."
Timo KiljunenAdjunct Professor and Medical Physicist, Docrates Cancer Center, Helsinki 
"We have been using MVision AI's autosegmentation software at the Oulu University Hospital since 2019 to all of our curative patients. We are happy to say that the quality of the segmentations is overall at a very good level and only minor adjustments have sometimes been needed to fit them in the clinical workflow. Software has lot of properties the competitors are not able to provide."
Juha NikkinenProfessor, Chief Physicist at Oulu University Hospital, Department of Oncology and Radiotherapy